

1. 구글 시트 데이터의 통합이 필요한 이유
구글 시트로 데이터를 관리할 때에 용량의 제한으로 연차 별, 분기 별로 구글 시트를 나누어서 관리할 수 밖에 없는 경우가 생깁니다. 이런 경우에 데이터 분석을 각 구글 시트 별로만 할 수 있는데, 피벗테이블을 사용하더라도 같은 구글 시트의 내용만 분석할 수가 있지요. 데이터의 양이 많은 경우에는 IMPORTRANGE를 사용해서 한 구글 시트에 모든 데이터를 가져올 수도 없습니다.
어떻게 하면 구글 시트들을 통합해서 연속적으로 분석할 수 있을까요?
바로, 빅쿼리(BigQuery)와 루커 스튜디오(Looker Studio)를 사용하는 것입니다.




구글에서 제공하는 두 서비스는 구글 시트들을 통합할 뿐만 아니라 다양한 각도에서 분석을 가능하게 해줍니다.
1.
여러 개의 구글 시트 데이터를 통합하고, SQL로 분석할 수 있습니다.
2.
빅데이터를 실시간으로 분석하고 리포팅 및 대시보드를 구축할 수 있습니다.
3.
데이터를 일관된 형식으로 표준화하고자 하고, 프로세스 자동화 등 기능을 구현할 수 있습니다.
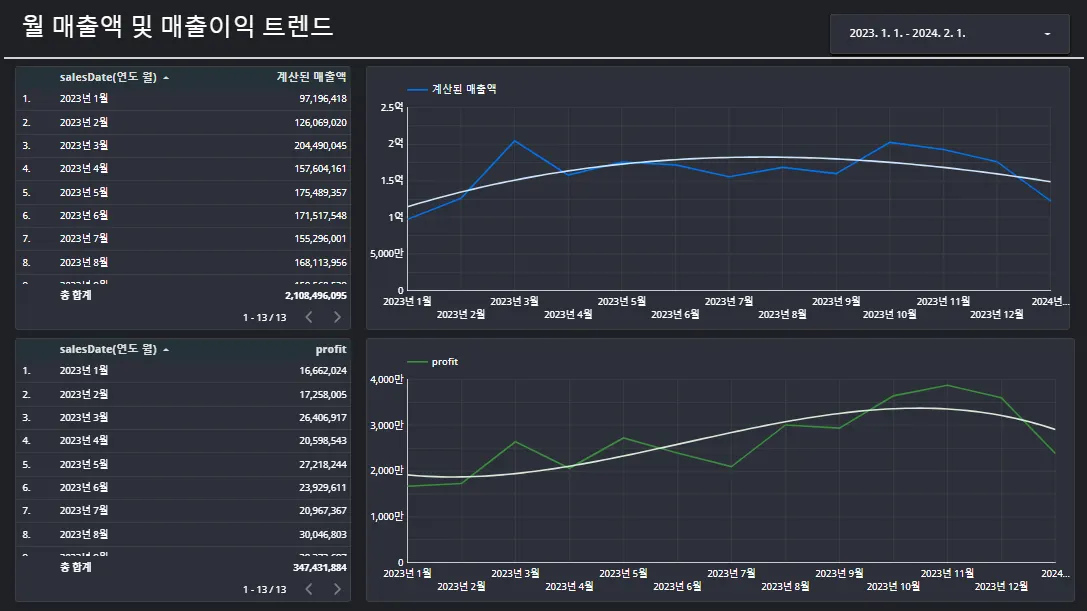
두 서비스를 활용하면 아래의 이미지처럼 분기 별 데이터를 통합하여 시계열 분석이 가능해집니다.
2. 구글 시트 데이터를 통합하는 과정
이제 빅쿼리와 루커스튜디오를 통해 스프레드시트의 데이터를 통합 및 시각화하는 방법을 간단히 소개하겠습니다.
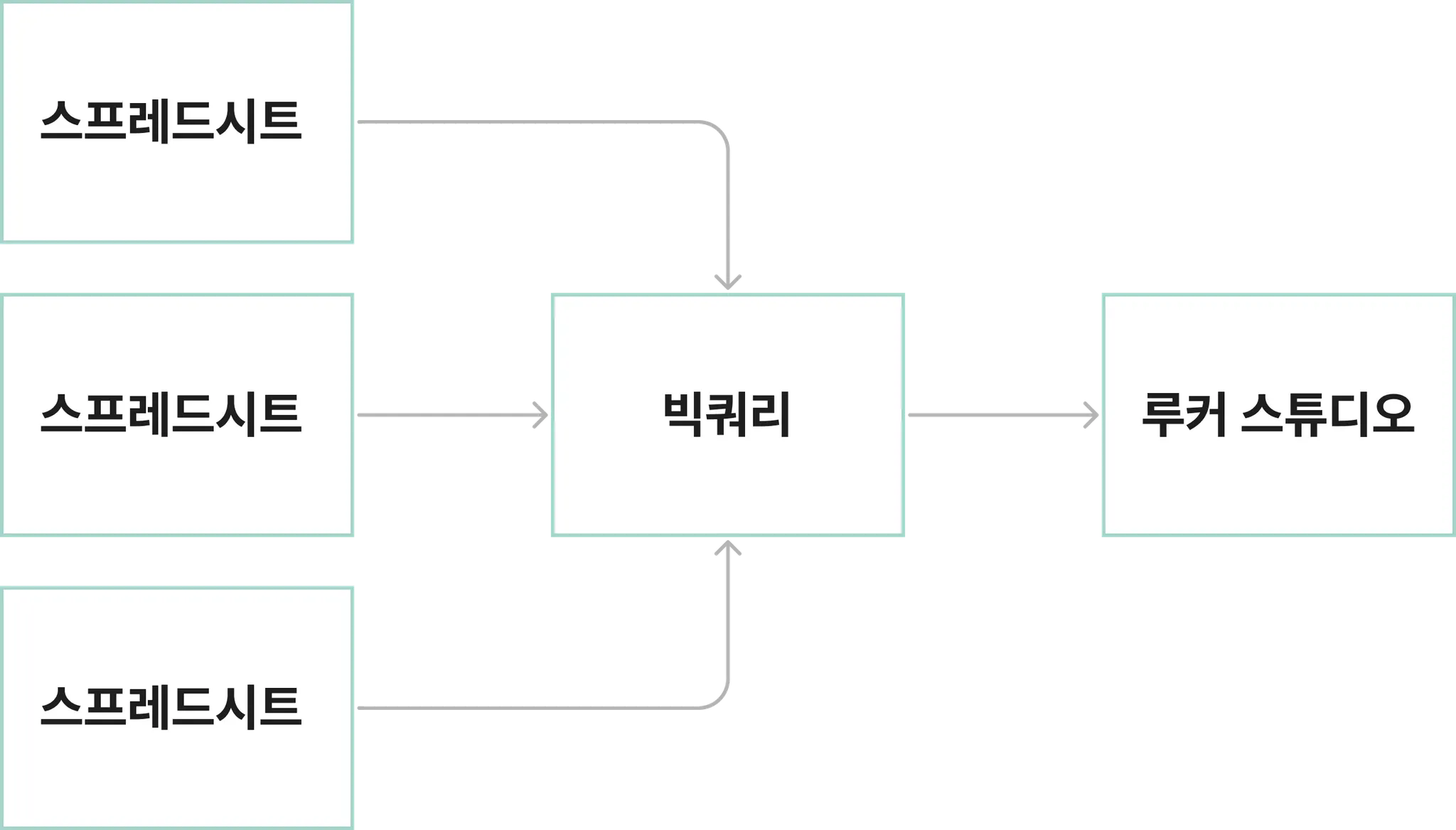
데이터의 통합 및 시각화 과정
2.1 먼저, 스프레드시트들을 빅쿼리에 연동합니다.
스프레드시트를 빅쿼리에 연동하면, SQL 쿼리를 사용해서 스프레드시트의 데이터를 빅쿼리에서 자유롭게 열람할 수 있습니다. 데이터를 가공해서 새로운 테이블을 만들 수도 있습니다.
2.2 다음으로, 빅쿼리 데이터를 루커 스튜디오에 연동합니다.
빅쿼리 데이터를 직접 또는 일부를 가공하여 루커 스튜디오에서 가져오면, 사용자가 원하는 통계나 데이터 시각 자료들을 만들 수 있습니다. 물론 약간의 세팅 작업이 필요합니다.
이제 구글 시트를 빅쿼리의 테이블로 만들고, 루커 스튜디오에 연동하여 차트를 그리는 방법을 자세하게 살펴볼까요?
3. 빅쿼리에 스프레드시트 연동하기
3.1 빅쿼리에 로그인 후, 프로젝트를 생성합니다.
프로젝트를 생성하기 위하여 상단의 ‘프로젝트 선택’을 클릭합니다.
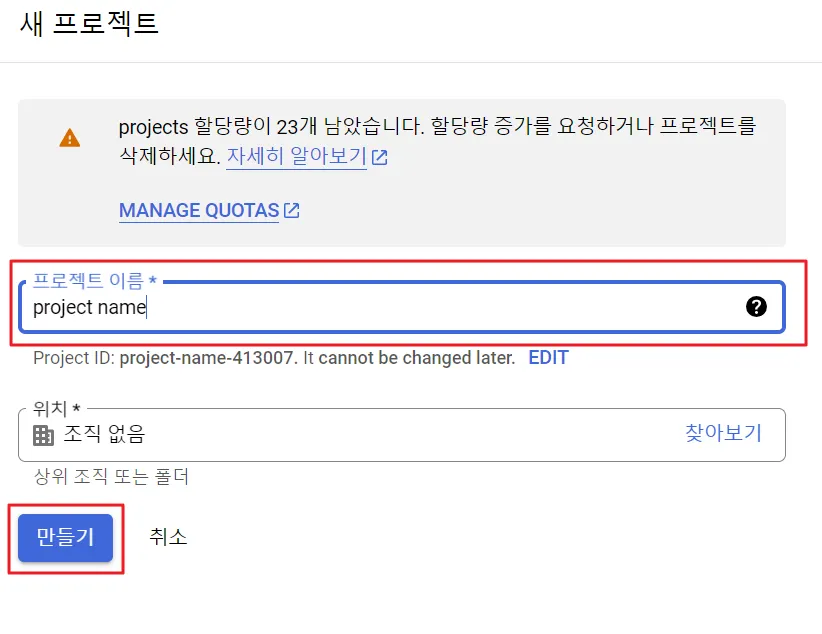
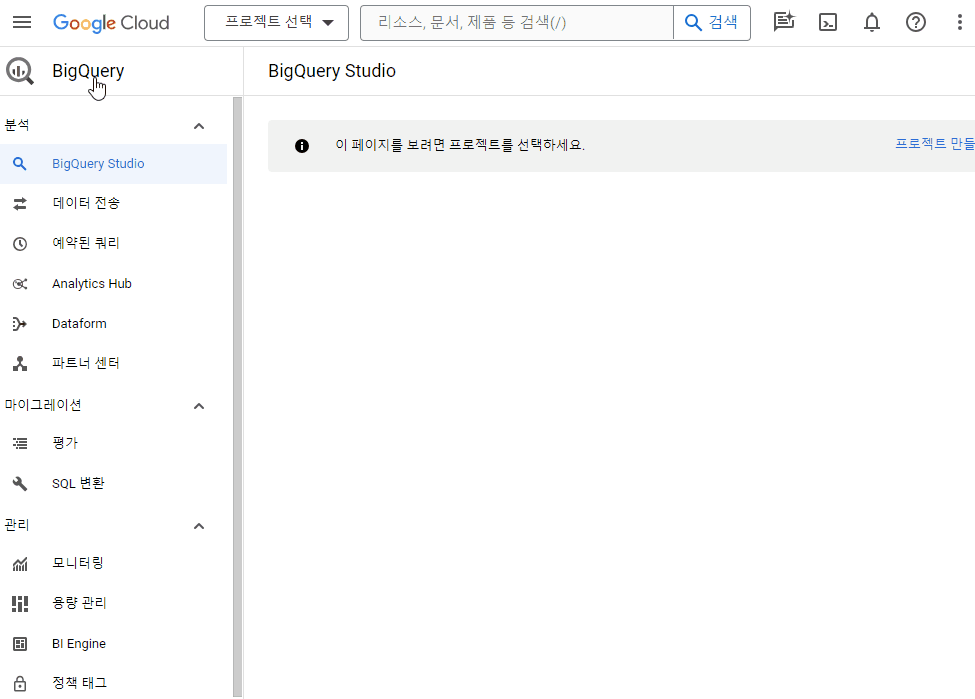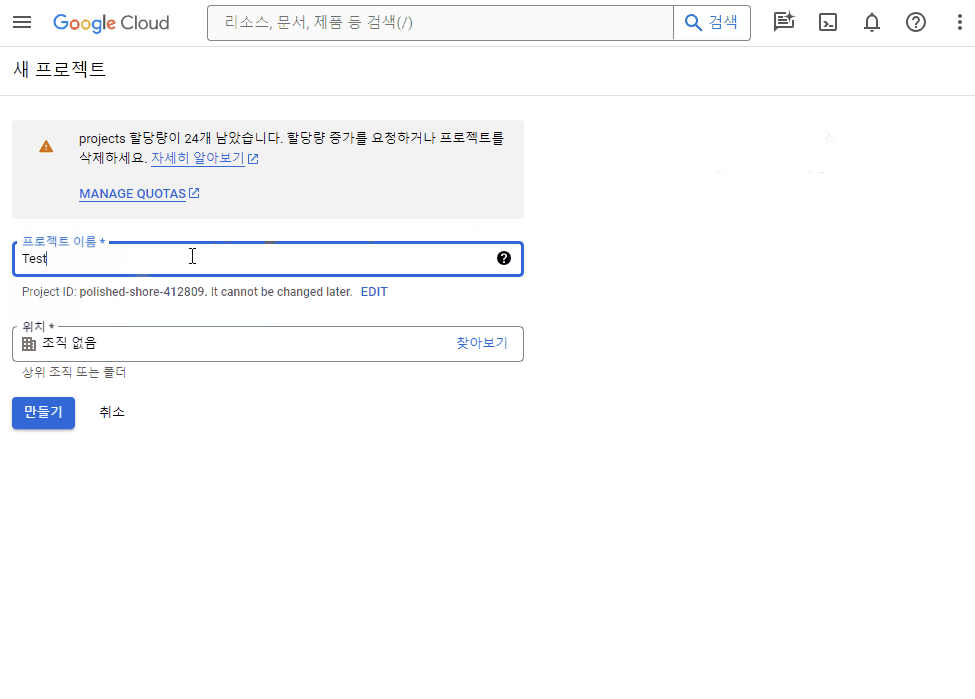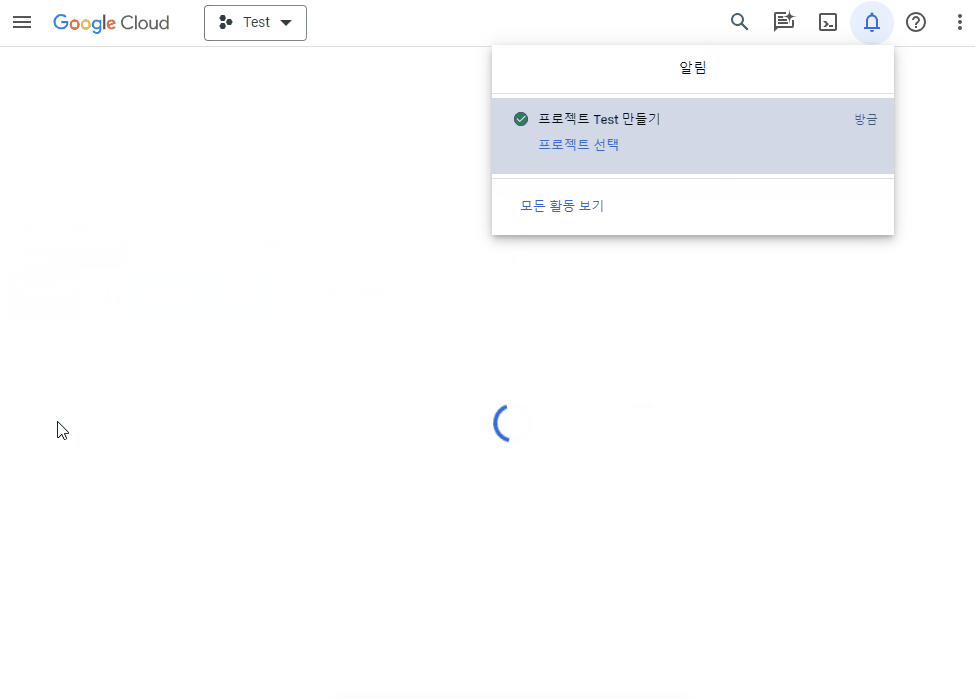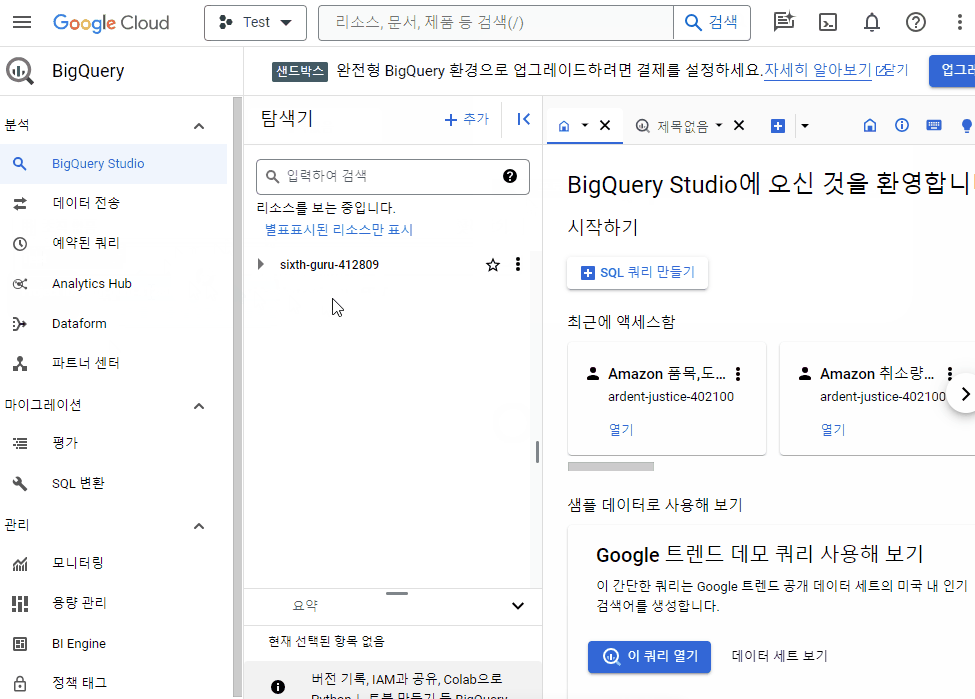
‘새 프로젝트’를 클릭합니다.
새 프로젝트 이름을 기입한 뒤 ‘만들기’ 버튼을 클릭합니다.
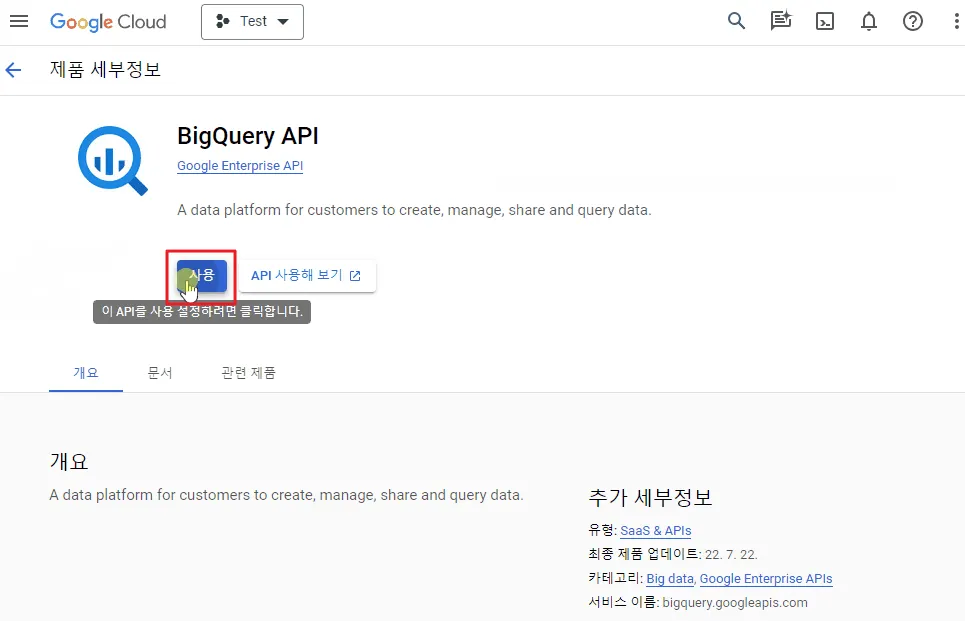
BigQuery API 사용 승인 창으로 연결될 경우, ‘사용’ 버튼을 클릭하면 빅쿼리 생성이 완료됩니다.
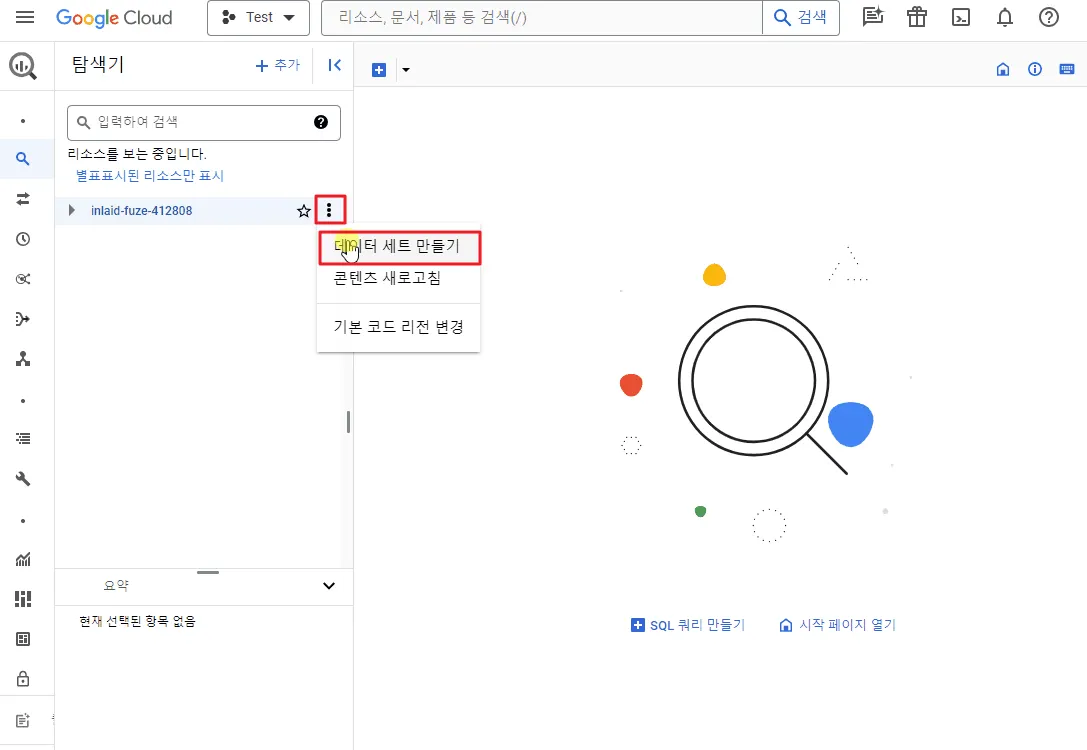
3.2 데이터세트를 생성합니다.
탐색기에 있는 프로젝트 옆의 점 3개 표시를 클릭 후 ‘데이터 세트 만들기’ 버튼을 클릭합니다.
데이터세트 설정 창이 나옵니다. ‘데이터세트ID’를 설정하고 위치 유형과 리전을 아래와 같이 설정합니다. 설정이 모두 완료되면 ‘데이터세트 만들기’ 버튼을 클릭합니다.
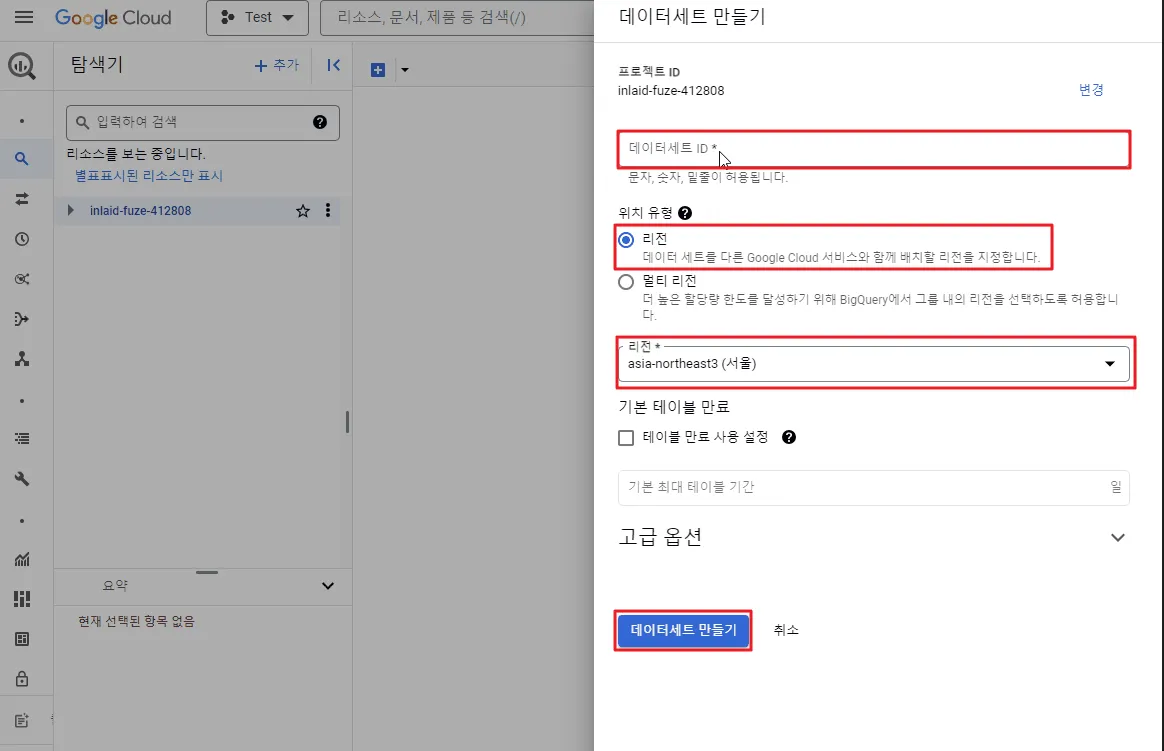
‘데이터세트ID’, ‘위치 유형’, ‘리전’ 설정 후 ‘데이터세트 만들기’ 클릭
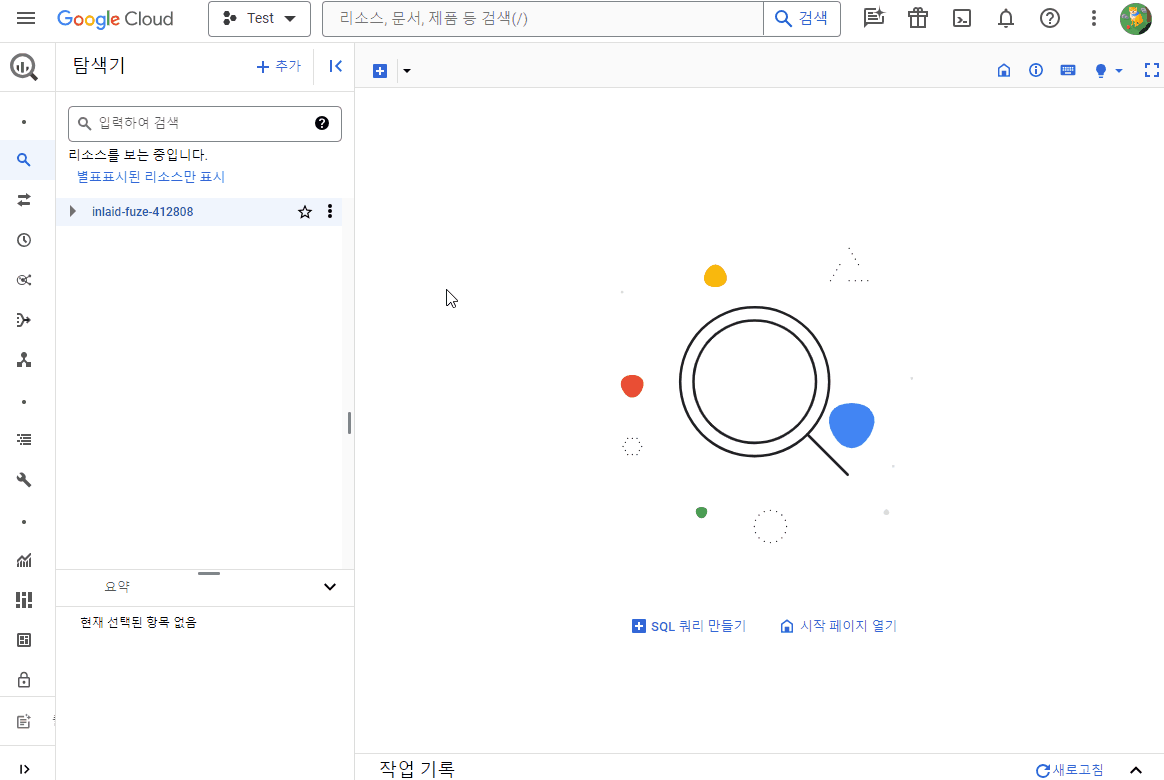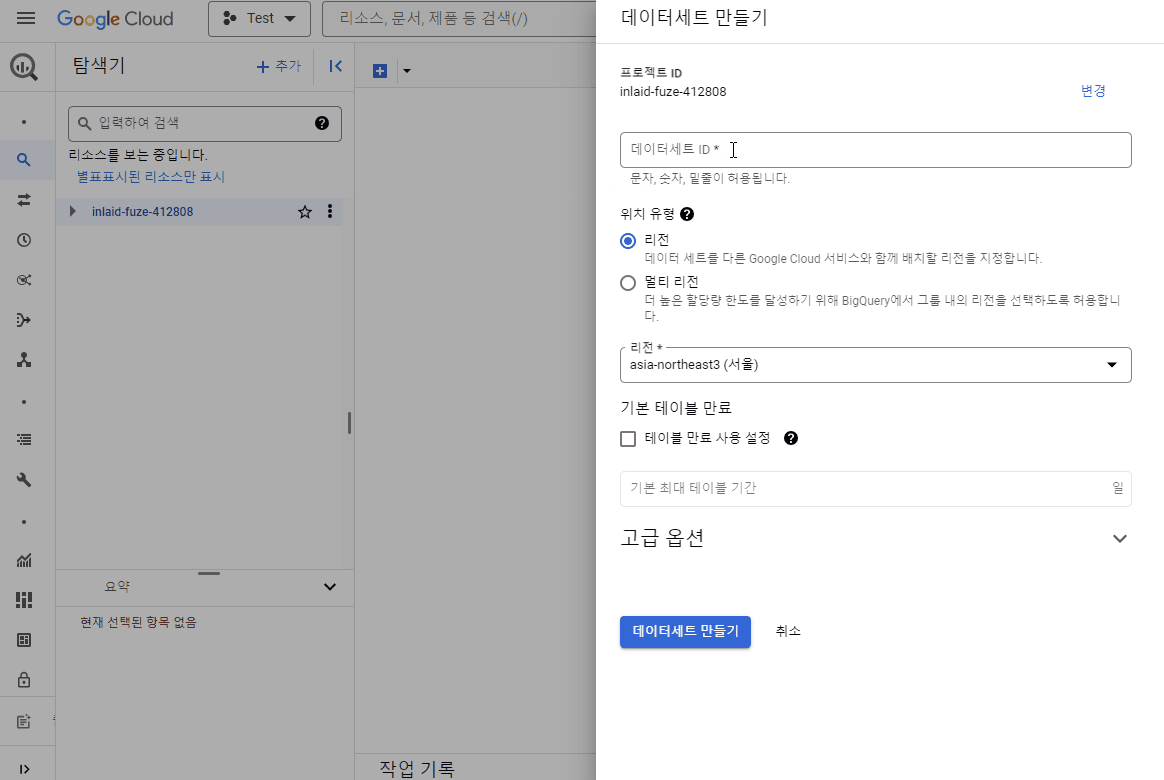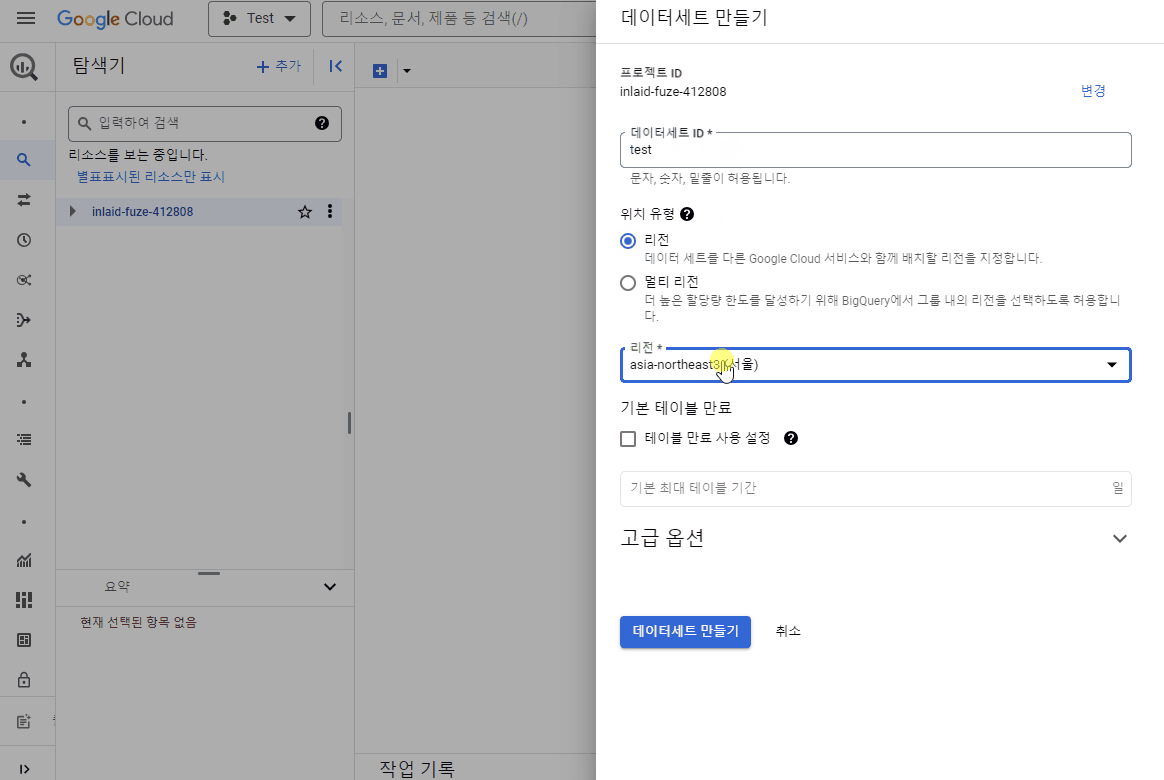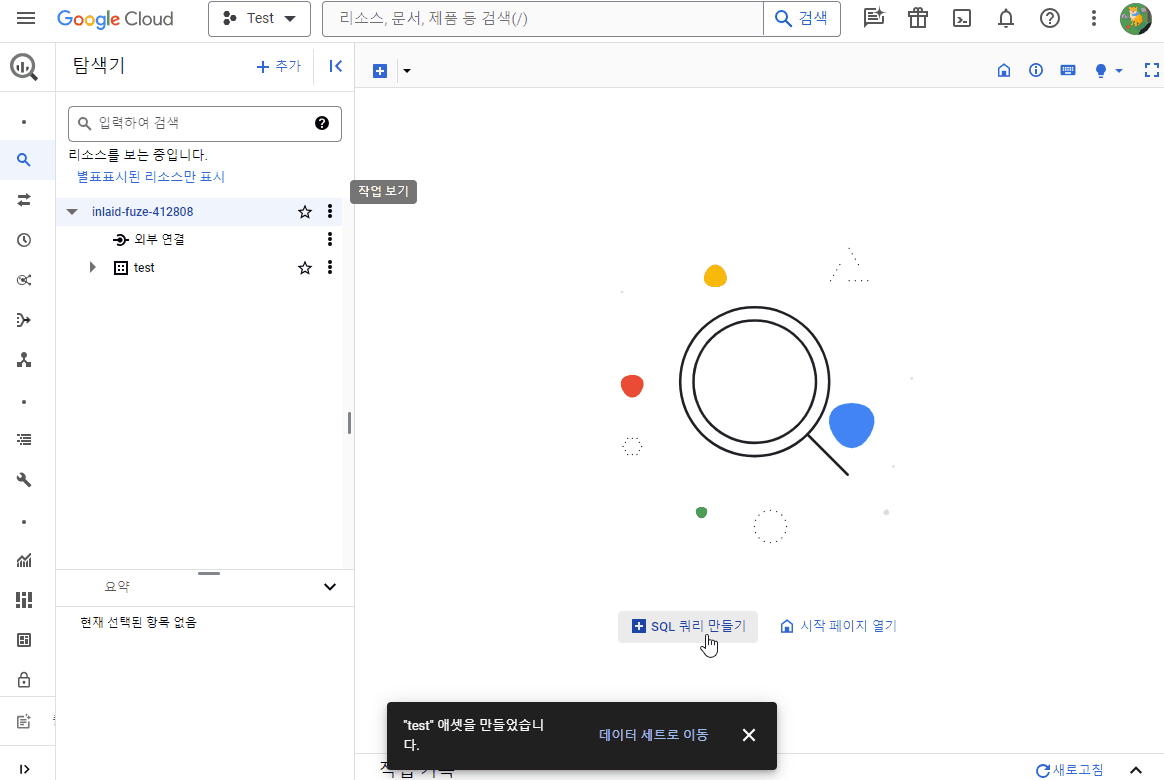
‘데이터세트 만들기 - 데이터세트ID 기입 - 리전 선택(서울) - 데이터세트 만들기’ 클릭
여기서 생성된 데이터세트는 폴더와도 같습니다. 스프레드시트에서 각각의 시트를 이 데이터세트 안에 담을 수 있기 때문입니다. 스프레드시트에 있는 시트를 방금 생성한 데이터세트 안으로 가져와볼까요?
3.3 데이터세트 하위에 테이블을 추가합니다.
먼저, 생성한 데이터세트 우측의 점 3개 버튼을 누르고 ‘테이블 만들기’ 버튼을 클릭합니다.
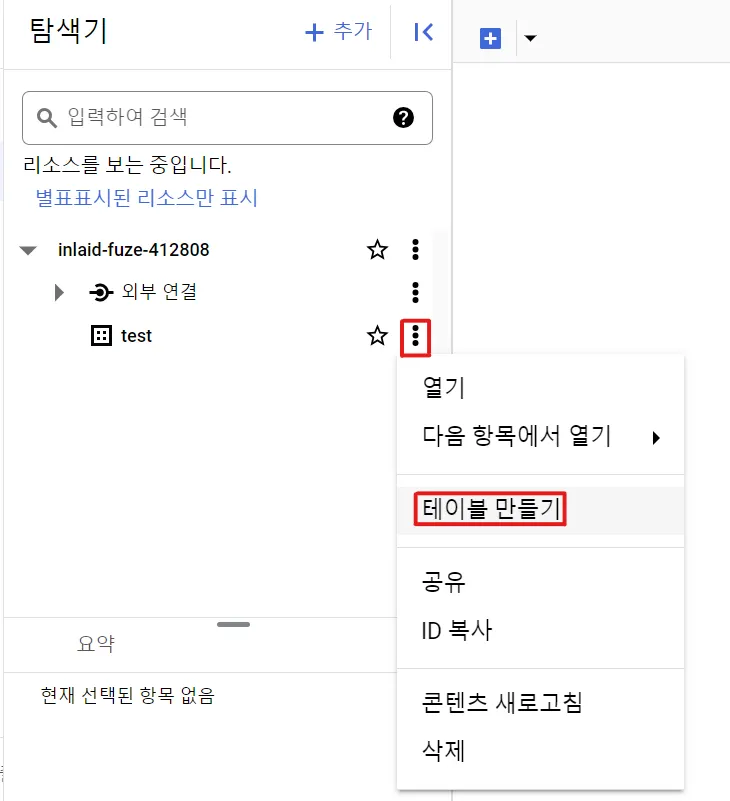
‘테이블 만들기’ 클릭
다음으로, 설정을 세팅하고 테이블을 생성합니다.
사용자가 설정하여야 하는 부분은 다음과 같습니다.
•
테이블을 만들 소스: 스프레드시트가 구글 드라이브에 있으므로 ‘드라이브’를 선택합니다.
•
Drive URI 선택: 가져오고자 하는 스프레드시트의 URL의 ‘/edit#’ 전 까지의 주소를 입력합니다.

‘구글 시트의 URL 중 /edit#gid=0’ 라고 써있는 부분 앞까지의 주소를 입력합니다.
•
파일 형식: 스프레드시트인 ‘Googls Sheets’를 선택합니다.
•
시트 범위: 시트의 범위를 지정합니다. 예를 들어 아래의 데이터를 가져오고자 한다면 시트 범위의 입력값은 ‘2022!A:E’ 입니다. ‘2023’시트를 가져오고자 한다면 ‘2023!A:E’가 입력값이 되겠죠?
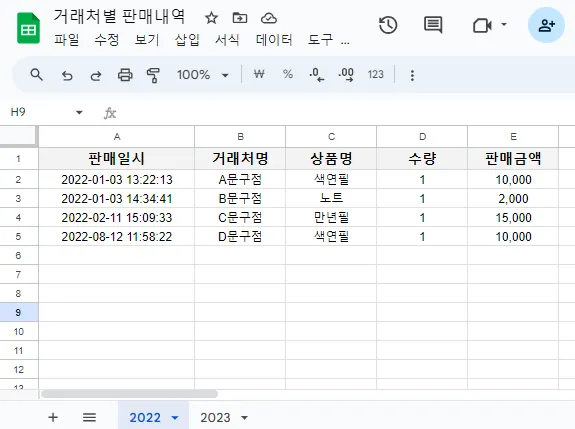
데이터 범위는 ‘A:E’ 처럼 연속된 셀로만 가져올 수 있습니다.
•
테이블: 빅쿼리의 데이터세트 안에 생성될 테이블의 이름을 입력합니다. 사용자가 알아볼 수 있도록 입력하면 됩니다.
•
스키마: 스키마는 각 데이터들의 열 제목 또는 헤더를 의미합니다. 자동감지를 하더라도 항상 잘 작동하는 것이 아니기 때문에 ‘텍스트로 편집’ 또는 수동으로 추가하는 것이 정확합니다.
빅쿼리에서 스키마는 한글을 사용할 수 없기 때문에, 스프레드시트의 헤더(열 제목)는 빅쿼리에 불러올 때 변환해주어야 합니다. 예제에서는 salesDate(판매일시), client(거래처명), product(상품명), Qty(수량), salesPrice(판매금액)로 정의하였습니다. 데이터 형식 역시 문자(STRING)인지 숫자(INTEGER)인지 지정해주어야 합니다. 위 예시의 입력 값은 다음과 같이 설정할 수 있습니다.

•
고급옵션 → 건너뛸 헤더 행: 스프레드시트에서 헤더 행을 제외합니다. 예시에서는 헤더가 1개의 행이기 때문에 ‘1’을 입력하였습니다.  중요한 부분인데, 건너뛸 헤더 행을 지정하지 않으면 스프레드시트에 있는 각각의 헤더가 데이터로 분류되는 불상사가 발생합니다. 꼼꼼한 설정이 필요하겠죠?
중요한 부분인데, 건너뛸 헤더 행을 지정하지 않으면 스프레드시트에 있는 각각의 헤더가 데이터로 분류되는 불상사가 발생합니다. 꼼꼼한 설정이 필요하겠죠?
중요한 부분인데, 건너뛸 헤더 행을 지정하지 않으면 스프레드시트에 있는 각각의 헤더가 데이터로 분류되는 불상사가 발생합니다. 꼼꼼한 설정이 필요하겠죠? 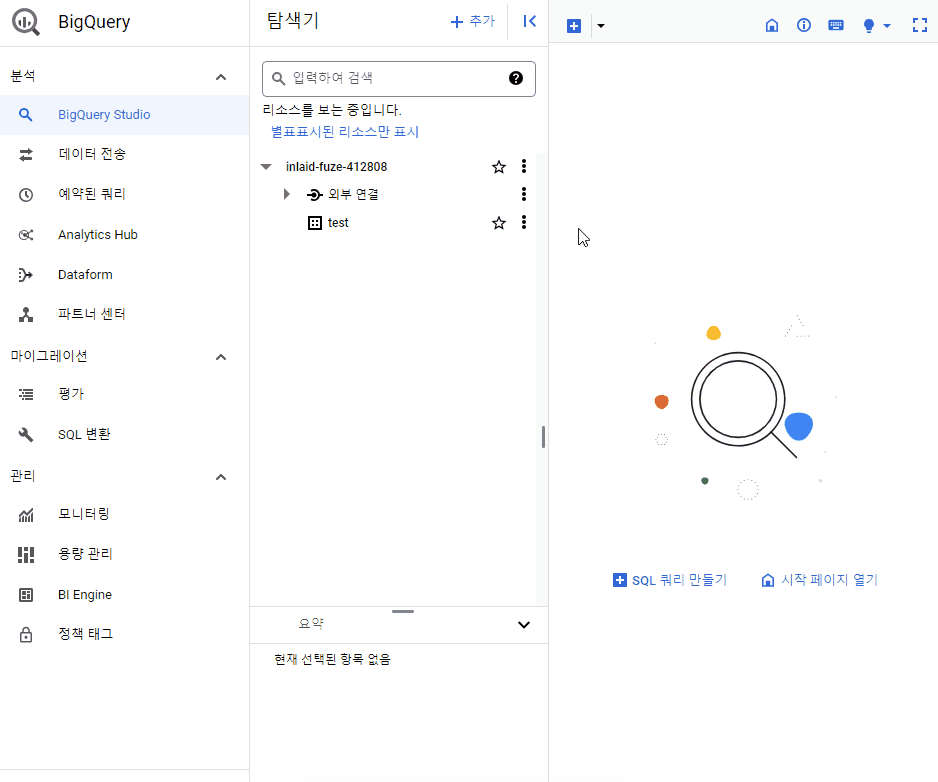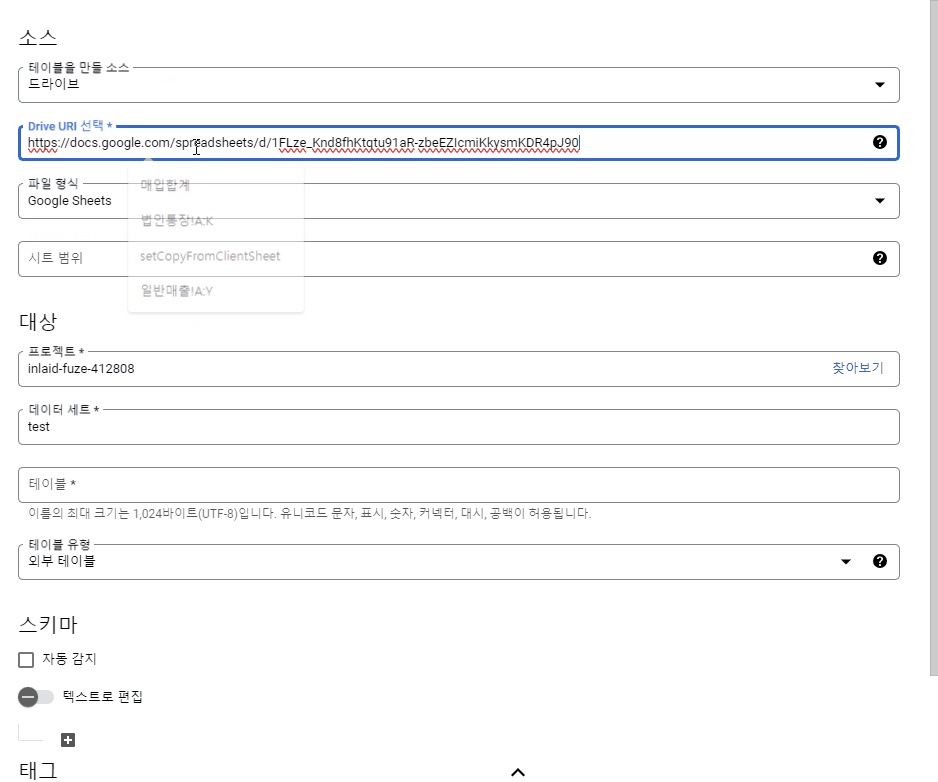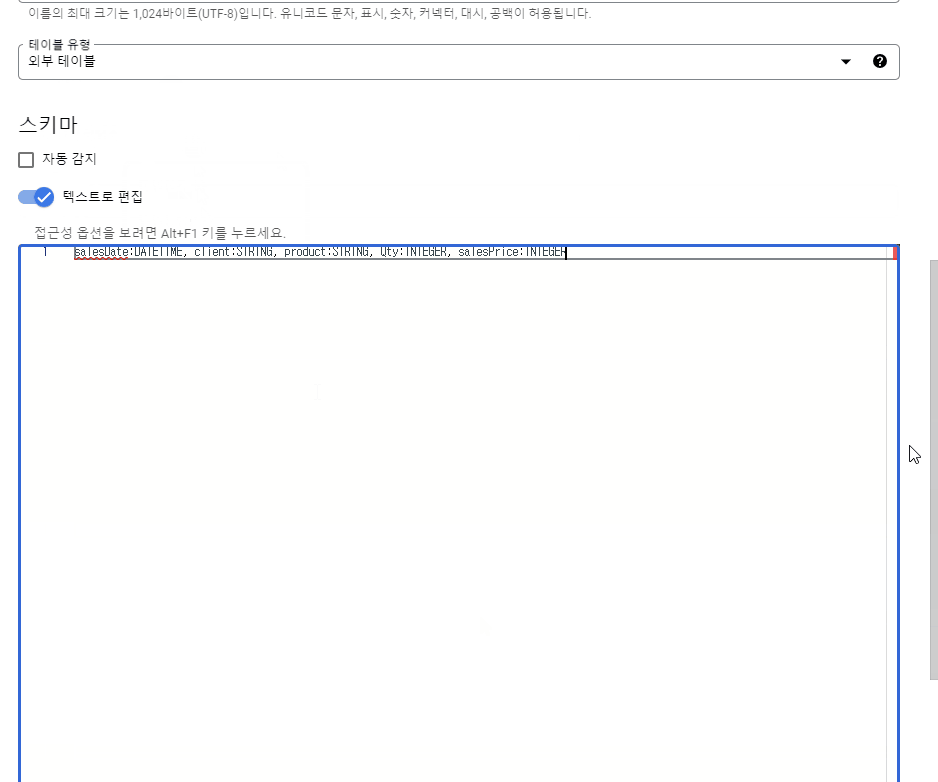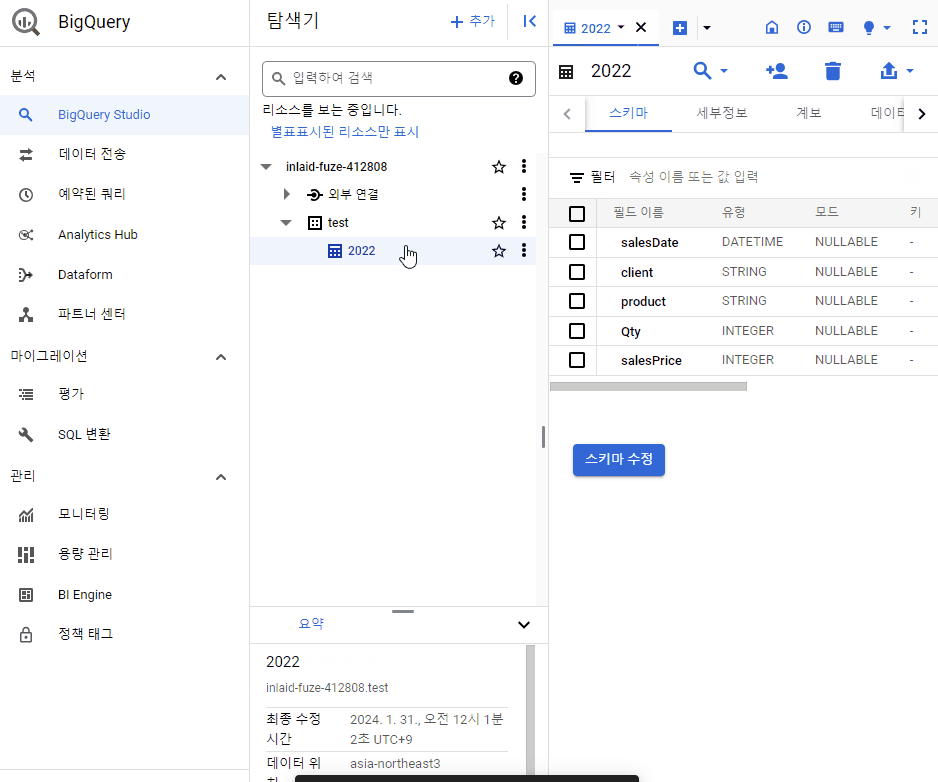
설정 예시
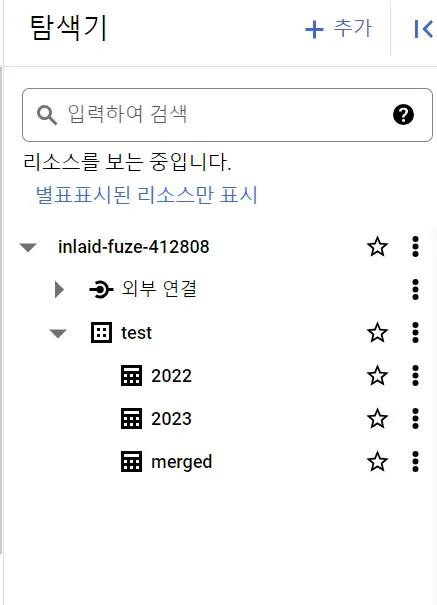
4. 빅쿼리에 연동한 구글 시트들을 1개의 테이블로 합치기
빅쿼리에 구글 시트를 연동한 테이블을 생성하면 쿼리문을 사용하여 데이터를 원하는 대로 불러와서 루커 스튜디오에 데이터를 연동할 수 있습니다. 하지만 데이터를 분석하고 통계를 산출하고 시각화를 하기 위한 데이터들은 한 개의 시트로는 충분하지 않은 경우가 대부분입니다. 관리하는 데이터가 방대할수록 시트의 개수도 늘어나기 마련이지요.
이제 빅쿼리에 연동한 구글 시트들을 1개의 테이블로 합치는 방법을 살펴보겠습니다.
다음의 쿼리는 2022, 2023 두 테이블을 합쳐서 하나의 결과 집합으로 반환합니다. 합쳐진 결과 집합에는 두 테이블의 모든 행이 포함되며, 각 테이블의 데이터가 그대로 유지됩니다.
중복된 행을 포함하려면 UNION ALL을 사용하고, 중복을 제거하려면 UNION만 사용할 수 있습니다.
SELECT * FROM `inlaid-fuze-412808.test.2022`
UNION ALL
SELECT * FROM `inlaid-fuze-412808.test.2023`
SQL
복사
데이터 합쳐서 불러오기
이제 다음의 쿼리로 두 테이블을 합친 결과로 새로운 테이블 merged를 생성해보겠습니다. 이미 테이블을 생성해둔 경우에는 CREATE TABLE 대신 INSERT INTO 를 사용하여 테이블에 행을 추가할 수 있습니다.
CREATE TABLE `inlaid-fuze-412808.test.merged` AS
SELECT * FROM `inlaid-fuze-412808.test.2022`
UNION ALL
SELECT * FROM `inlaid-fuze-412808.test.2023`;
SQL
복사
통합한 데이터로 테이블 생성
이제 다음과 같이 merged 테이블을 탐색기에서 확인할 수 있습니다.
2022, 2023 테이블을 통합하여 merged 테이블을 생성
5. 루커 스튜디오에서 빅쿼리 테이블 불러오기
이제, 2022년 판매데이터, 2023 판매데이터를 통합한 ‘merged’ 테이블을 루커 스튜디오로 불러와서 데이터를 분석해보겠습니다.
5.1 빅쿼리를 데이터 소스로 보고서를 생성합니다.
루커 스튜디오 홈페이지에 접속한 후 ‘시작하기’ 버튼을 누르면 루커 스튜디오를 시작할 수 있습니다.

루커스튜디오 메인 화면으로 연결되었네요
루커 스튜디오의 메인 화면
좌측의 메뉴를 통해 새로운 보고서를 생성합니다.
‘만들기 - 보고서’ 클릭
연결할 데이터의 종류로 BigQuery(빅쿼리)를 선택합니다.
‘BigQuery’를 선택합니다.
빅쿼리에서 불러오길 원하는 테이블을 선택 후 ‘추가’ 버튼을 클릭합니다. 여기서는 test 데이터세트의 merged 테이블을 선택합니다.
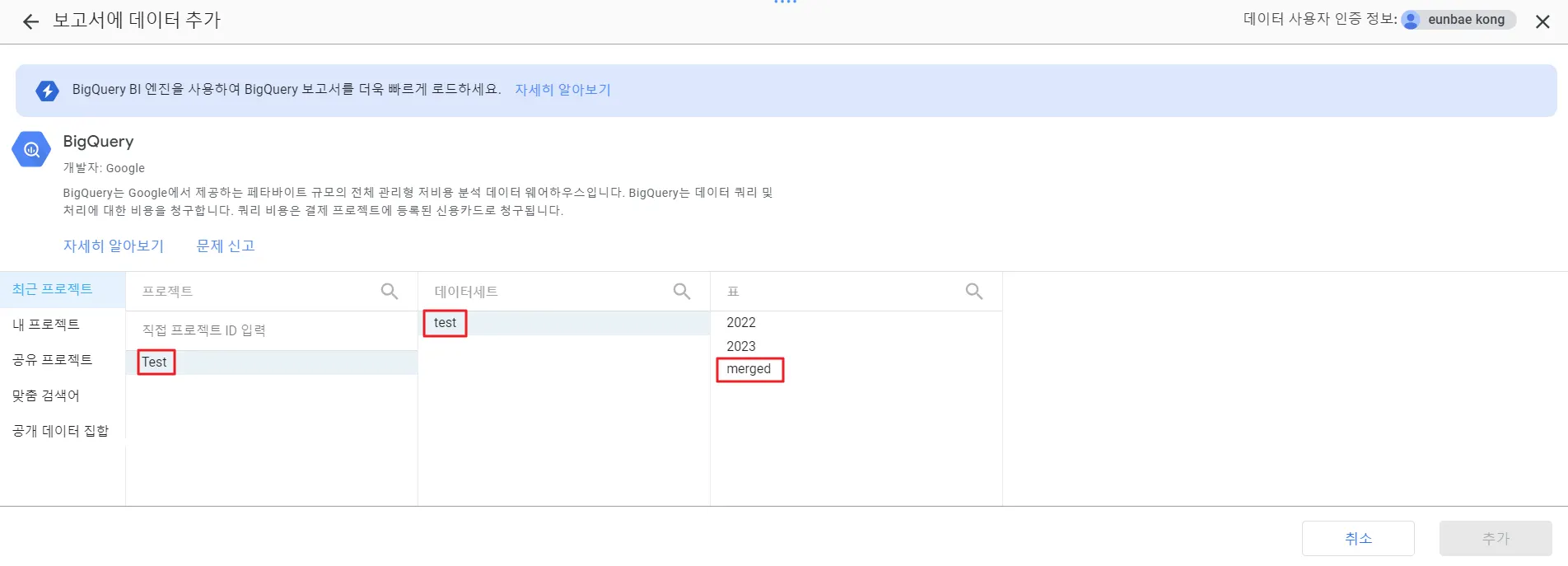
5.2 원하는 차트를 추가해서 분석합니다.
데이터를 불러왔으니, 필요에 맞게 차트를 그려볼까요? 우측 상단 빨간 박스 안 차트 버튼을 클릭하면 다양한 차트를 볼 수 있습니다.
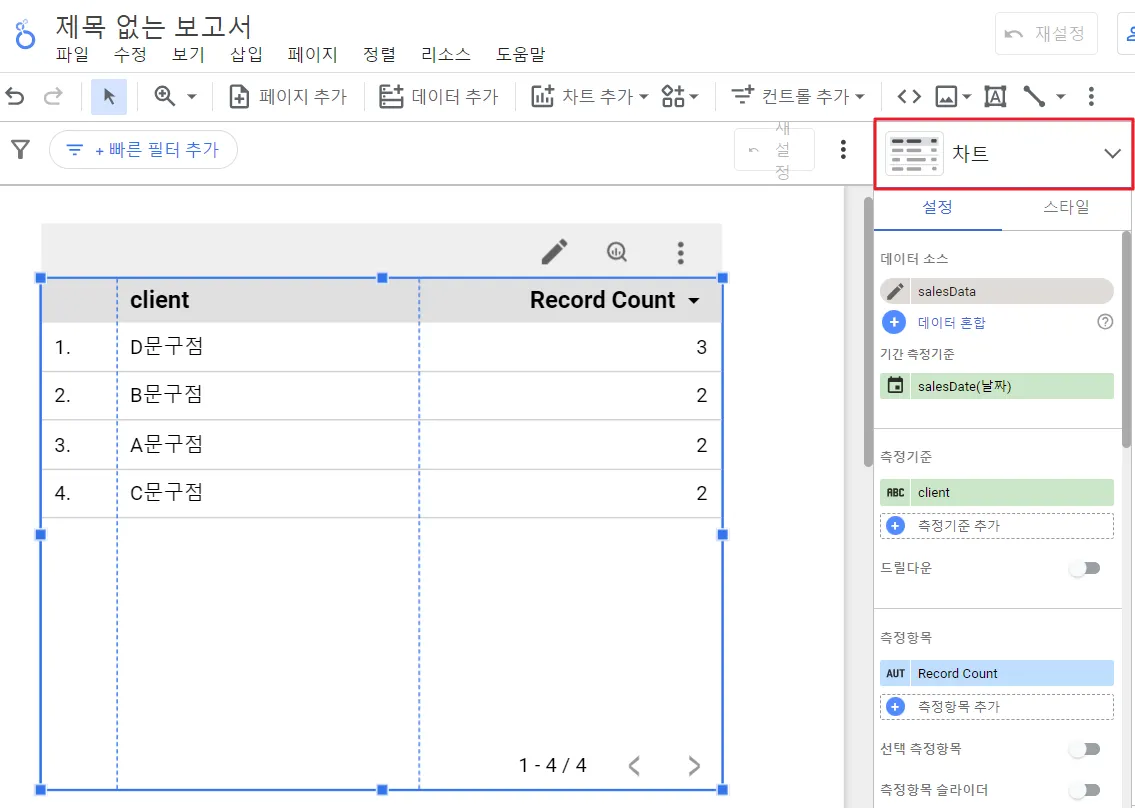
각각의 차트에 따라 요구되는 측정 기준, 측정 항목 값은 약간씩 다릅니다. 사용자는 데이터에 맞는 차트를 선택하고, 원하는 측정 기준과 측정 항목을 선택하여 데이터를 분석할 수 있습니다.
다양한 차트를 선택할 수 있습니다.
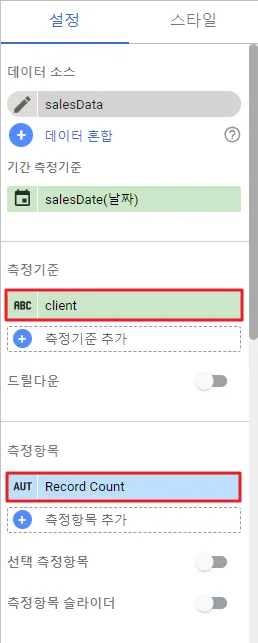
‘측정기준’과 ‘측정항목’을 설정할 수 있습니다.
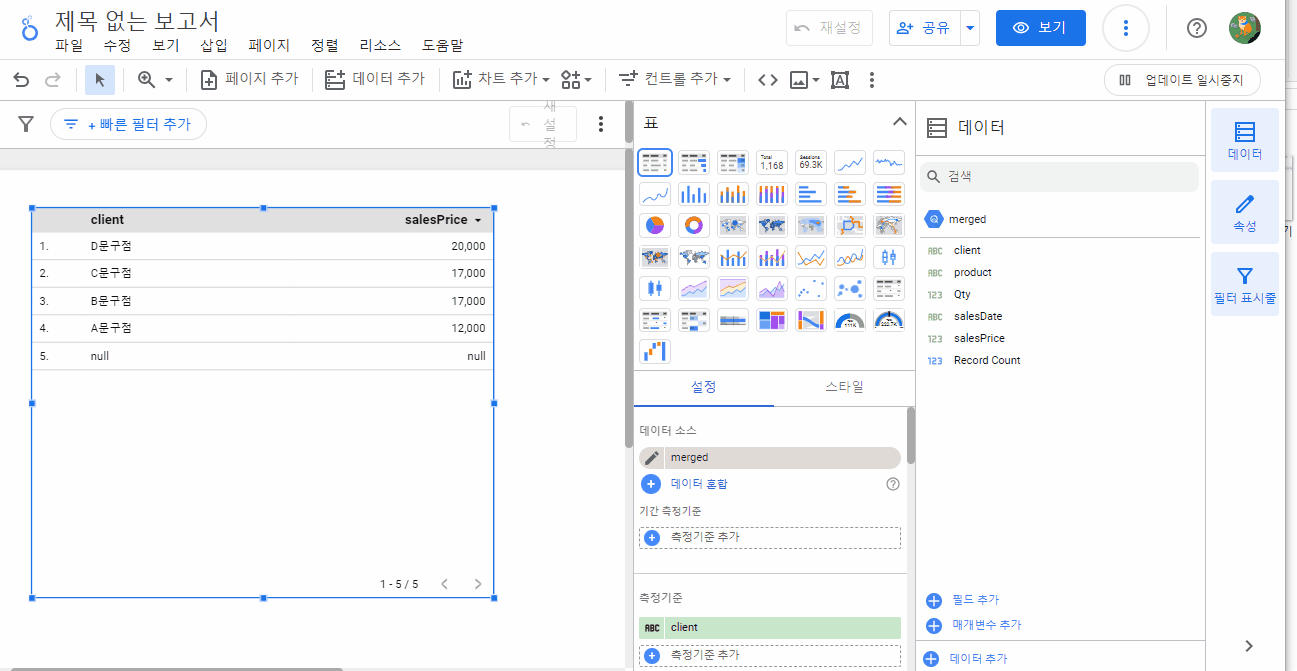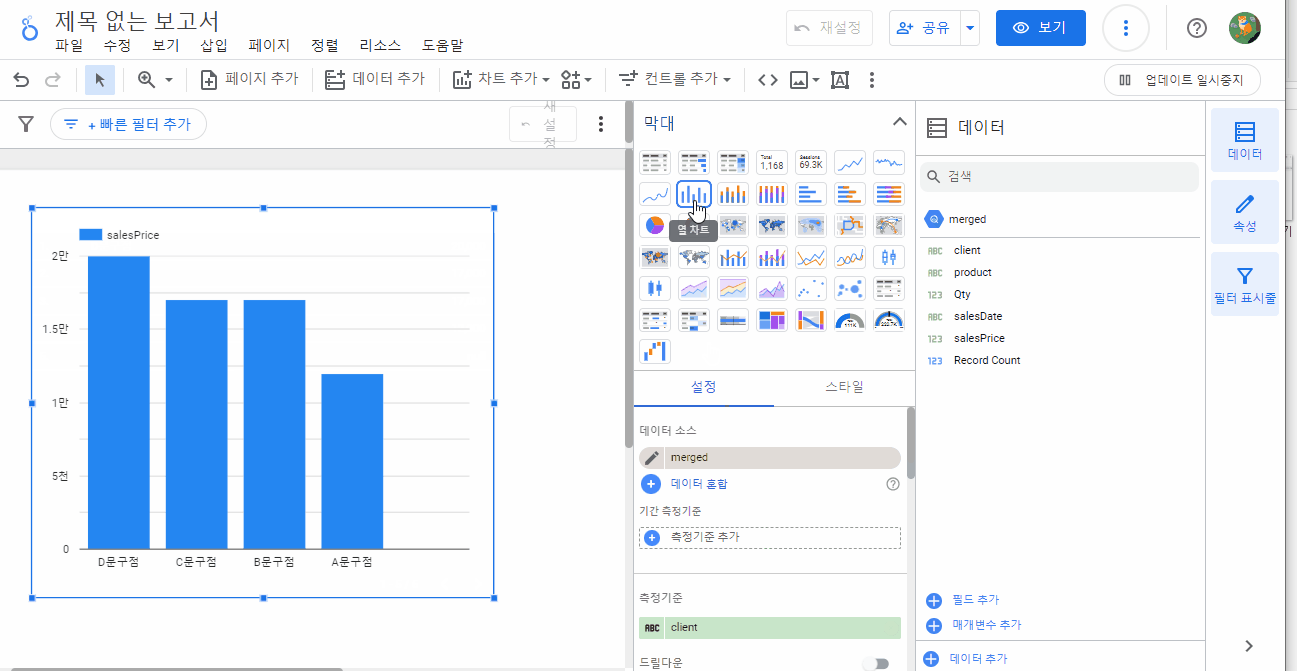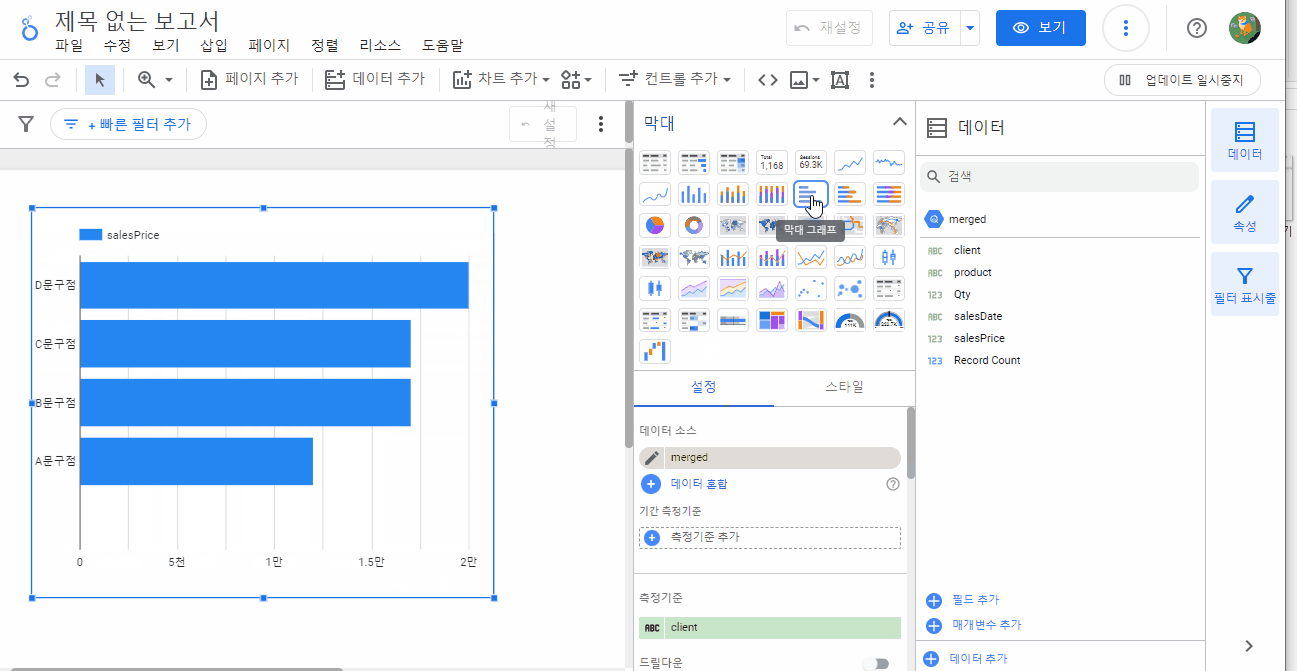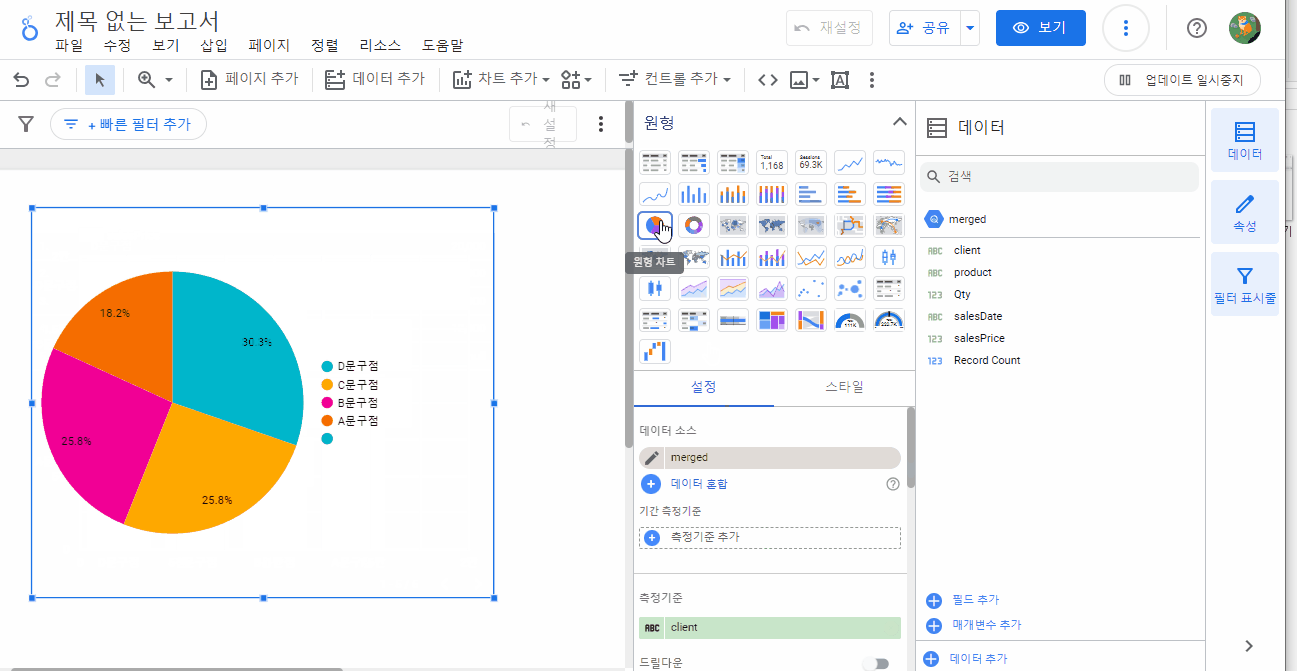
빅쿼리와 루커 스튜디오를 활용하여 구글 시트를 통합하고, 데이터를 시각화하는 방법에 대해 간략히 살펴보았습니다. 두 서비스를 활용하면, 구글 시트에서는 불가능한 분석 및 시각화가 가능합니다.
하지만 사용자가 데이터를 한번 통합한 데이터를 불러오기 때문에 통합 이후에 쌓인 데이터들은 위 차트에 반영이 되지 않을 것입니다. 차트를 보고 싶을 때마다 매번 최신 데이터를 보기 위해 데이터를 통합하는 작업이 필요할까요? 빅쿼리를 활용하면 이 작업도 자동화할 수 있습니다. 방법이 궁금하시다면 다음의 포스팅도 참고해보시길 바랍니다.
이번 포스팅에서는 빅쿼리와 루커 스튜디오의 기본적인 사용법을 다뤘지만, 두 도구에는 아직 살펴보지 않은 다양한 고급 기능들이 많이 숨겨져 있습니다. 데이터 분석의 깊이를 더하고 싶다면 두 서비스에 대한 학습과 훈련이 필요합니다. 앞으로 더 많은 데이터를 다루면서, 새로운 기능들을 익힐 수 있는 포스팅을 올리도록 하겠습니다.
